
マンションのデータを扱って行くために必要な基本的なスキルを身につけていきましょう。今回は後編です。今日は日本地図のデータから東京都と神奈川県を選び、この2都県を対象に土地利用と都心からの距離の関係性をみていくことにしましょう。この演習を通して、空間検索やバッファの作成などを学びます。
1. データの準備
(1)まずデータをダウンロードしましょう。
(2)ダウンロードしたzip ファイルを解凍します。解凍できない場合は、7-ZipやLhasa32などのファイル圧縮・解凍ソフトウェアをインストールします。解凍したデータは演習1で作ったspatialanalysisというフォルダに格納します。
以下データ一覧です。
| データ項目名 | データセット名 | データ形式 | ファイル名 | 備考 |
|---|---|---|---|---|
| 土地利用データ | lu1994gc | Img形式 | lu1994gc.img lu1994gc.rrd | 1994年細密数値情報 (出典)国土地理院(有償) |
| データ項目名 | データセット名 | データ形式 | ファイル名 | 備考 |
|---|---|---|---|---|
| 東京中心点 | 東京中心点 | shp形式 | 東京中心点.shp 東京中心点.dbf 東京中心点.prj 東京中心点.shx 東京中心点.sbn 東京中心点.sbx | なし |
2. 前回の演習データを開く
(1)spatialanalysis(演習1で作成したフォルダ)の中に保存しておいた、no2.qgsをクリックして開きます。
(2)下図のように表示されましたか。表示されたらOKです。表示されてなければ(3)に進んでください。
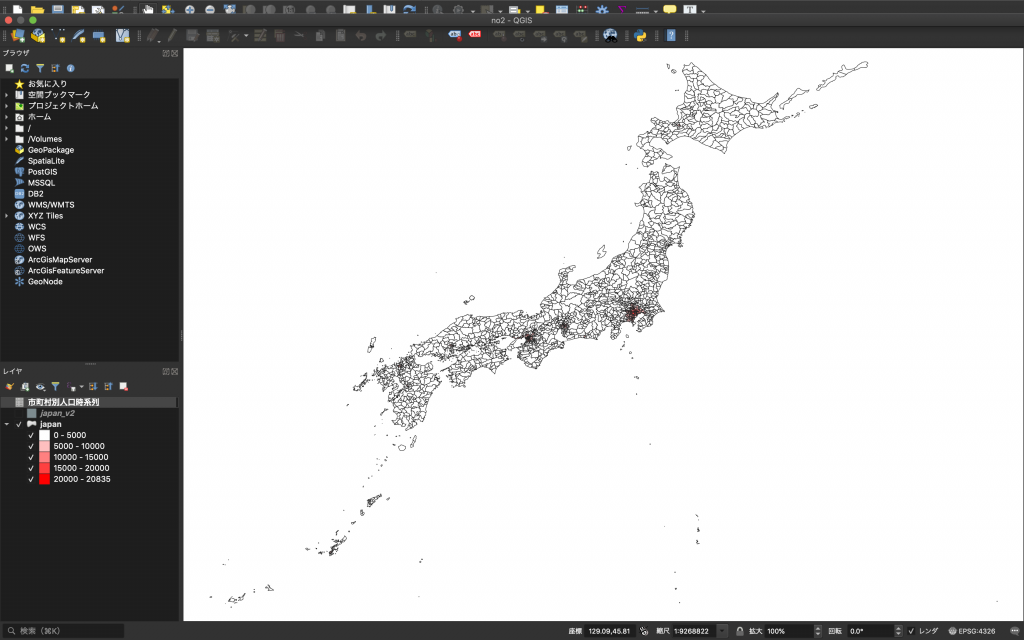
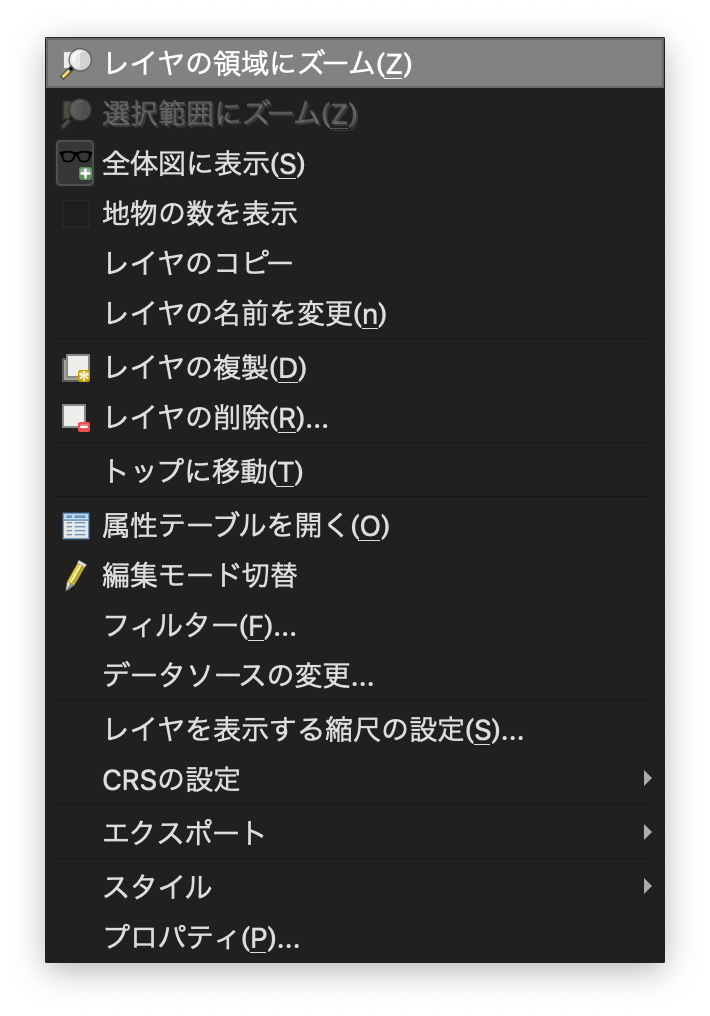
(3)レイヤウインドウの中にあるjapanを右クリックし、「レイヤの領域にズーム(Z)」をクリックします。
3. 属性選択
早速、今回のメインテーマです。GISデータを必要なエリアだけに絞るには、「必要なエリアを選択」し、「選択されたGISデータをエクスポート」します。ではどのように「必要なエリアを選択」すればいいでしょうか。ここではこの方法を習得していきます。
(1) 今回は、日本地図のうち東京都と神奈川県のデータだけに絞ります。japanを右クリックし、「属性テーブルを開く」をクリックします。開けたら属性テーブルのメニューにある「式を使った地物を選択」をクリックしてみましょう。
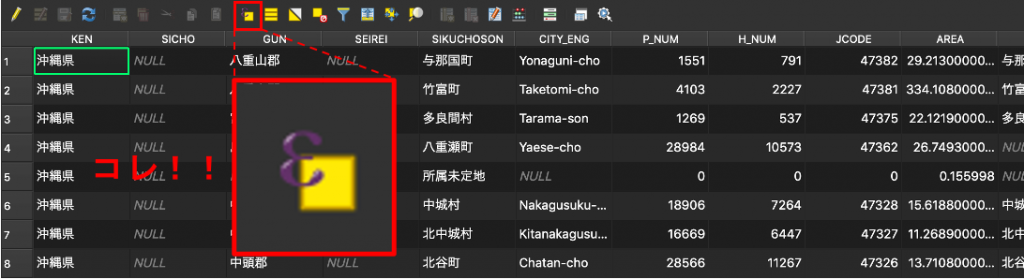
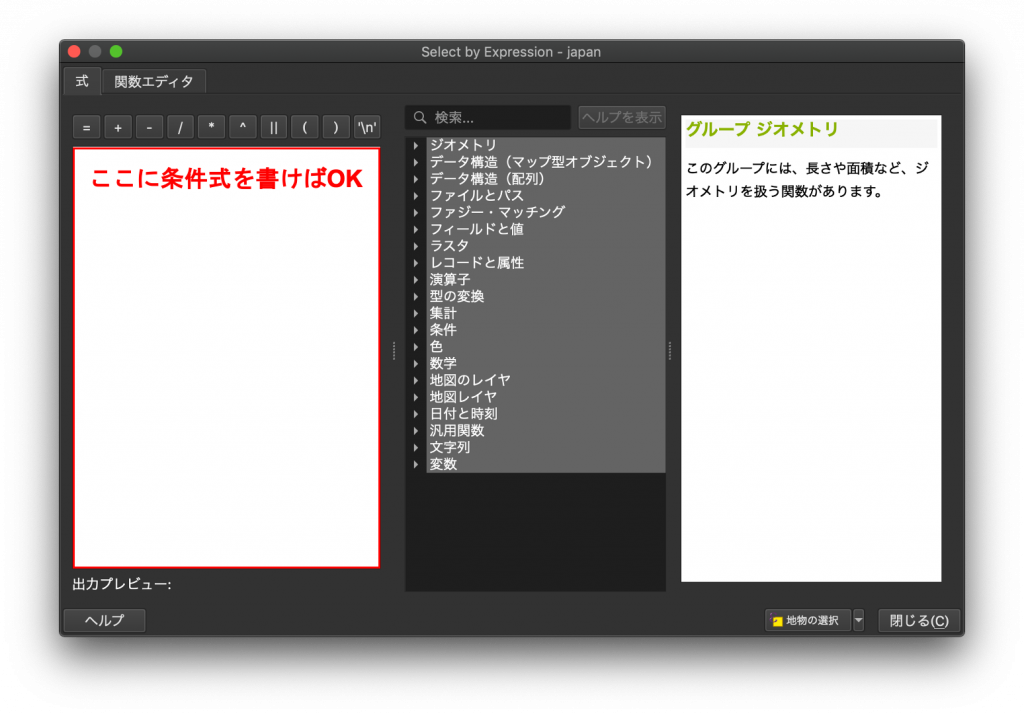
(2) 下図のような画面が開いたはずです。この赤枠のところに条件式を書くことで、属性に基づいて選択します。難しそうと思うかもしれませんが、四則演算(足し算とか引き算とか)できれば問題ありません。
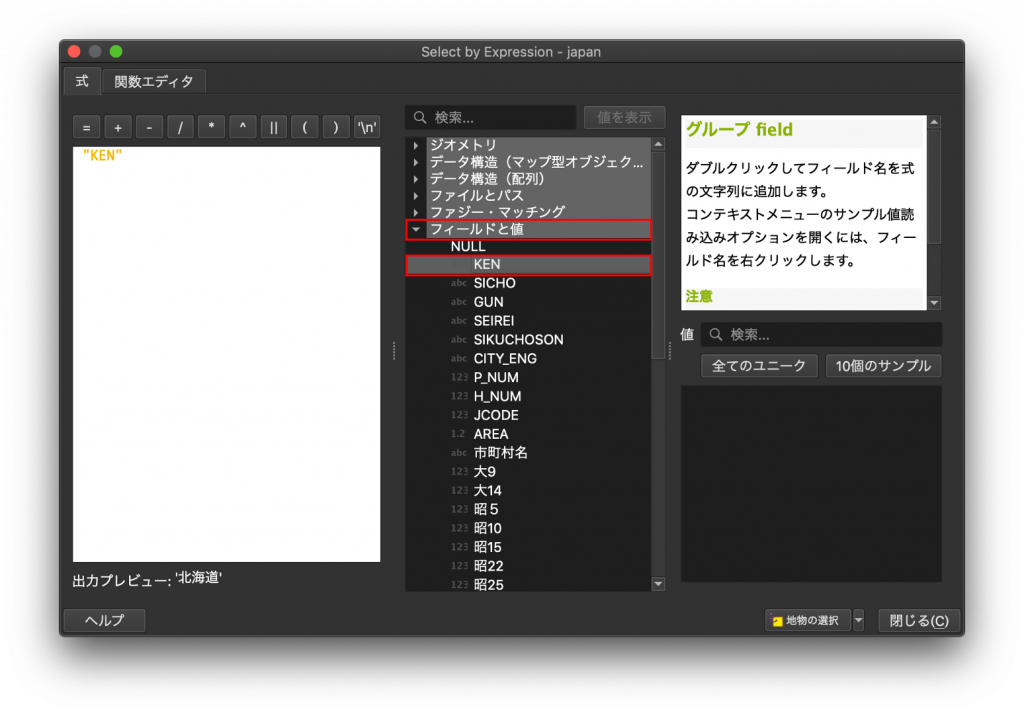
(3) 条件式は、全てタイピングして入力することも可能です。しかし、ミスタイピングのリスクがあります。そこで真ん中のウインドウと右のウインドウを使って、入力していきましょう。まず、真ん中のウインドウから「フィールドと値」を選びましょう。そうすると、下に属性のフィールド名(列の名前のこと)が出てきます。今回は都道府県の分類から東京都と神奈川県を選ぶので、KENをダブルクリックします。そうすると左のウインドウに「”KEN”」と入力されているはずです。
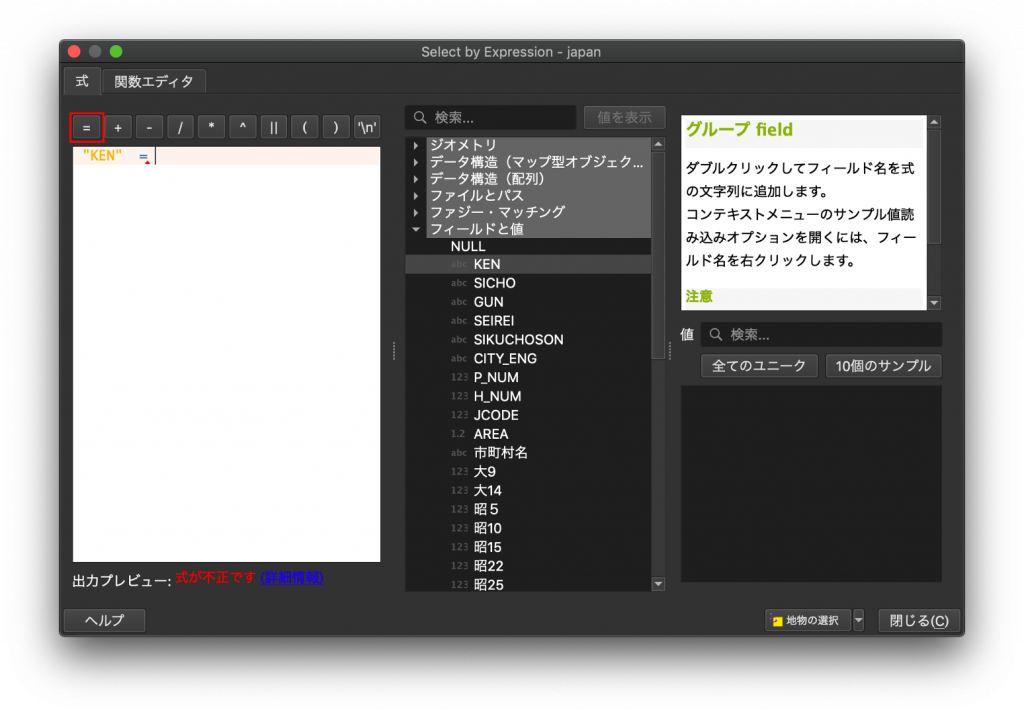
(4) 「”KEN”」が東京都と神奈川県を選択したいので、まずは左のウインドウの上にある記号のうち「=」をクリックします。そうすると「”KEN” =」となっているのではないでしょうか。
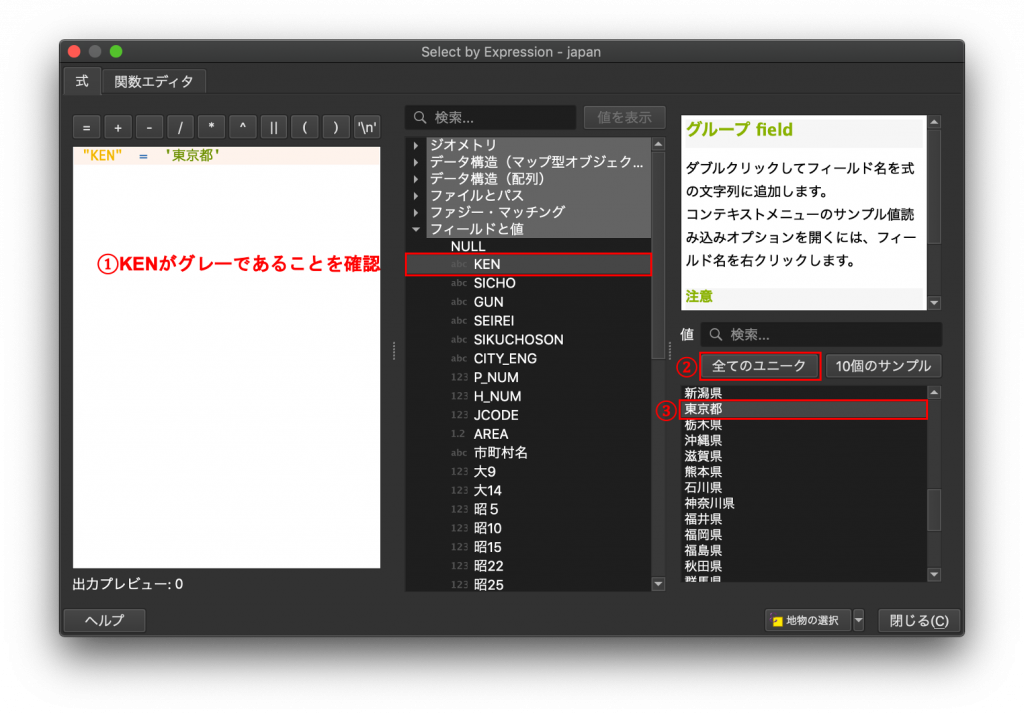
(5) 次に真ん中のウインドウで「KEN」が選択されている状態で、右中央にある「全てのユニーク」をクリックしましょう。そうすると右下にKENにある値の一覧が出てきます。そこから東京都をクリックすると、左のウインドウは「”KEN” = ‘東京都’」になっているのではずです。
(6) 続いて神奈川県を選択する条件文を書いていきます。このとき「OR」という演算子を使います。ORにするのは「都道府県の中で東京都『もしくは』都道府県の中で神奈川県」という意味にするためです。「ANDはダメですか」という質問もあるでしょう。こうした質問をする人の頭の中には「都道府県の中で東京都『と』神奈川県」という捉え方があるのだと思います。実はORやANDなどの演算子の前後では、条件式が単独で成立する形にしなければなりません。つまり、「都道府県の中で東京都『と』神奈川県」を条件式にした「”KEN” = ‘東京都’ AND ‘神奈川県’」はエラーになってしまいます。なぜなら、ANDの左側は「”KEN” = ‘東京都’」となっており条件式が成立していますが、右側は「’神奈川県’」だけですので条件式が成立していないからです。そのため、「都道府県の中で東京都『もしくは』都道府県の中で神奈川県」を条件式にした「”KEN” = ‘東京都’ OR “KEN” = ‘神奈川県’」と書かなければなりません。
(7) では演算子「OR」を入力しましょう。真ん中のウインドウで一旦「フィールドと値」を閉じて、「演算子」を開き「OR」を選択します(「OR」は一番下にあります)。
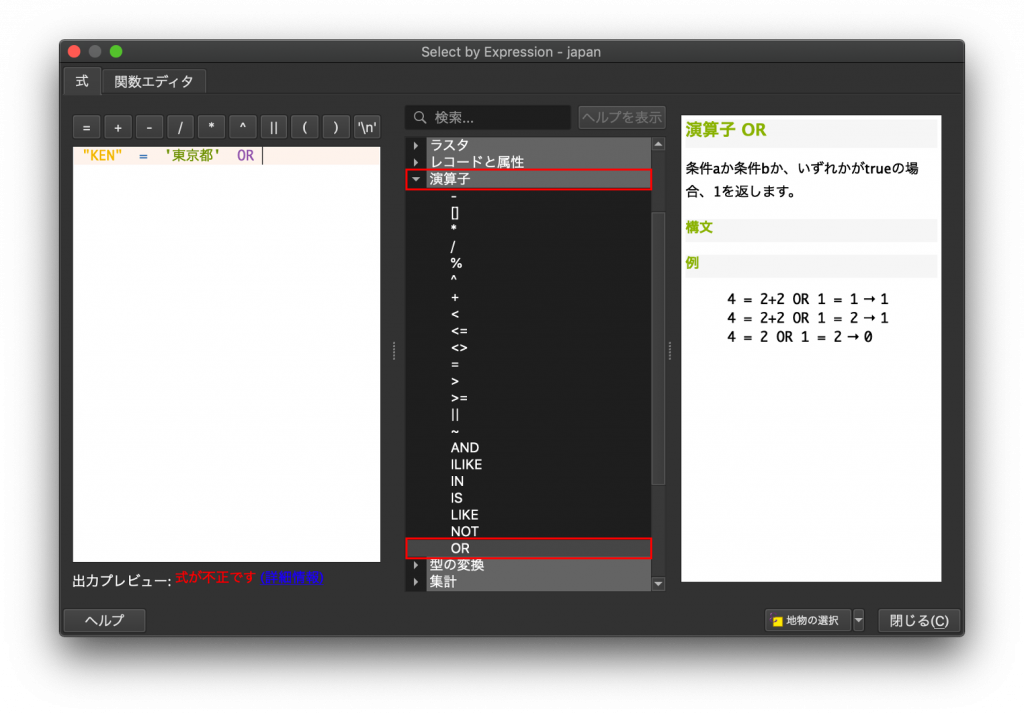
(8) 「OR」の後ろに「”KEN” = ‘神奈川県’」を入力してみましょう。要領は先ほどと同じです。
(9) 入力が終わったら、右下の「地物の選択」をクリックします。クリックしても画面は変わりませんが右の「閉じる」を押してこの画面を閉じます。また、属性テーブルも閉じます。
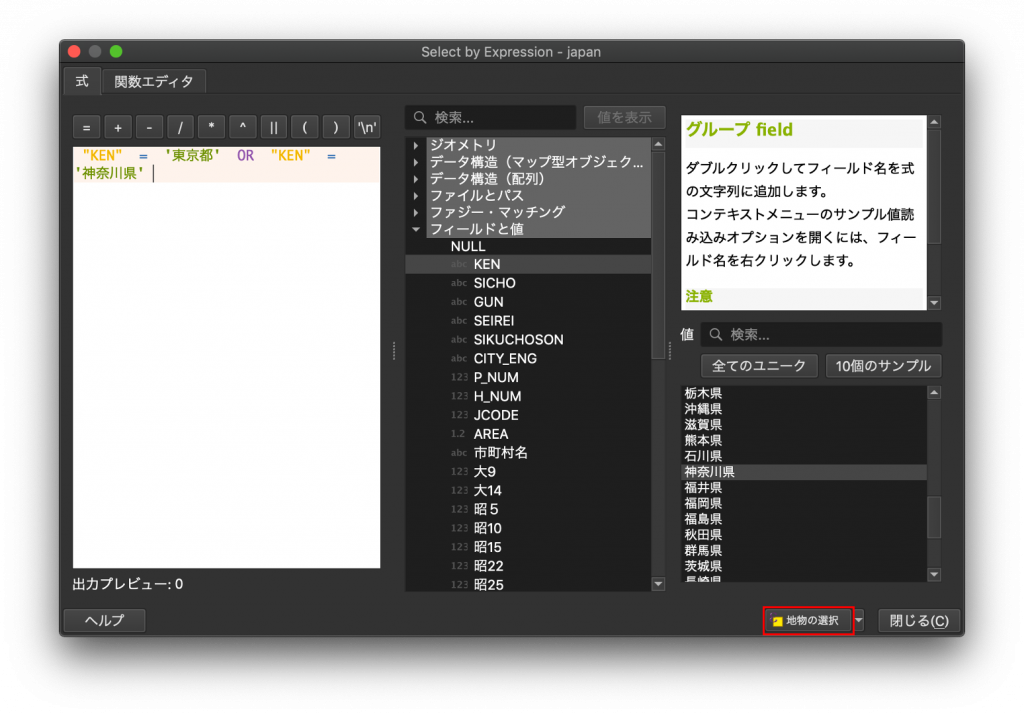
(10) そうすると、地図上で東京都と神奈川県が選択されていることが確認できます。
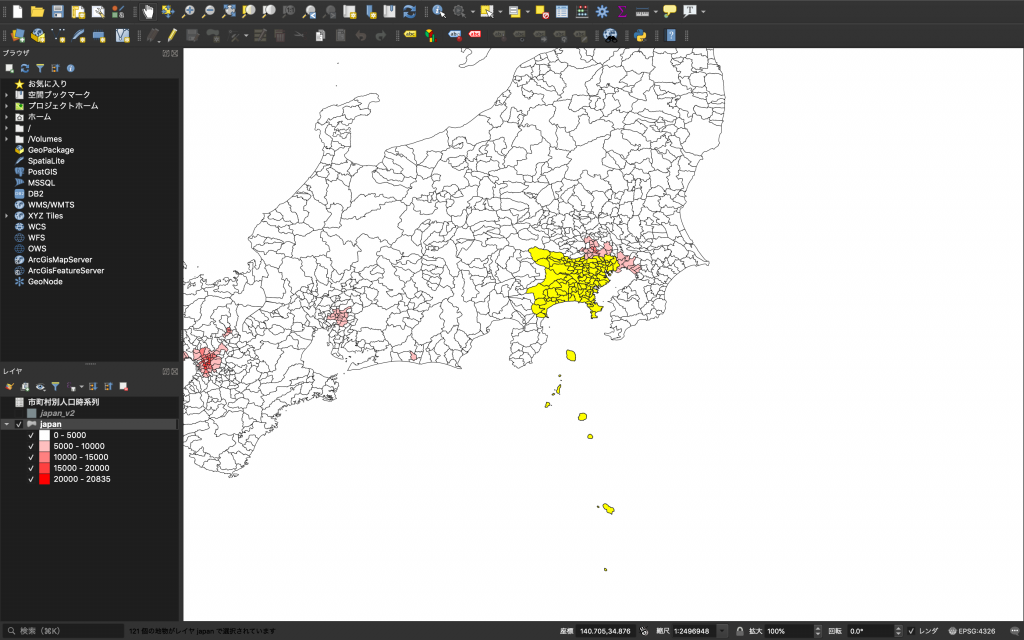
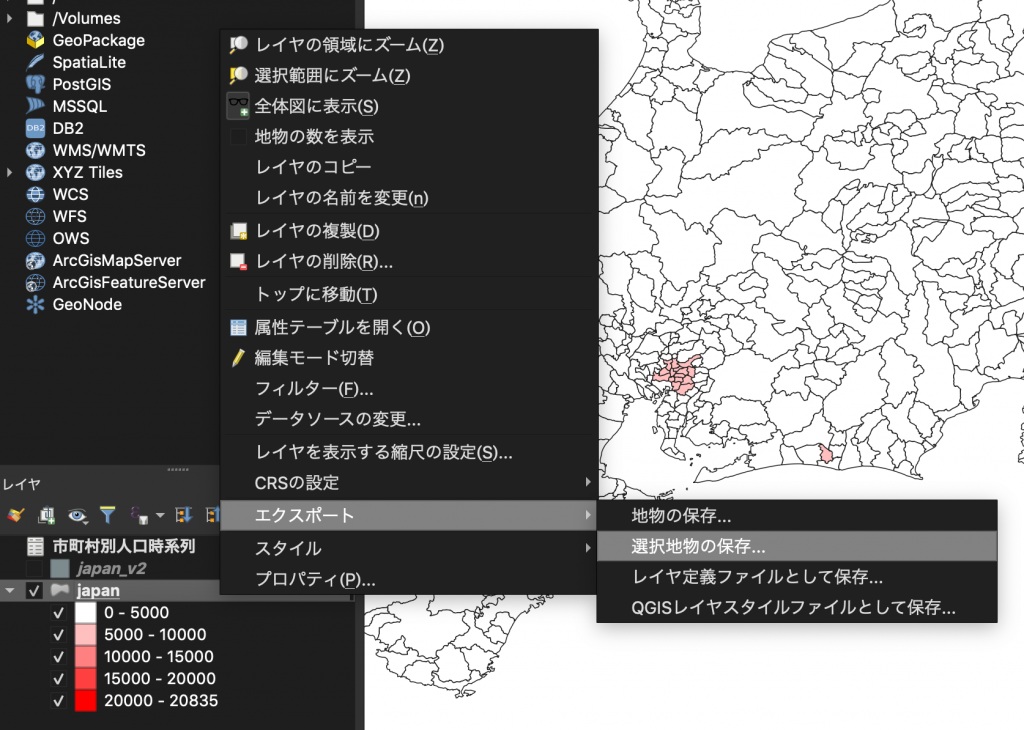
(11) 東京都と神奈川県が選択できることを確認したら、新規ファイルとしてエクスポートしましょう。「japan」を右クリックし、「エクスポート」→「選択地物の保存」を選びましょう。あとは前回同様に形式(ESRI Shapefile)やファイル場所(japan.shpと同じ場所に)と名前(本教材ではtokyo)を指定し、書き出せば選択したエリアのデータが出来上がります。
4. バッファを作ってみよう
バッファとは、任意の点やポリゴンから等距離のエリアのことです。ここでは東京の中心点(旧東京都庁を指すことが多い)からの距離を可視化してみましょう。
(1)はじめにダウンロードしたデータのうち「東京中心点.shp」をQGISで開きます。開き方は演習2の通りです。
(2) メニューバーから「ベクタ」→「空間演算ツール」→「バッファ」を選択します。

(3) 開いた画面では距離の単位が「度」になっています。なぜでしょうか。これは座標系と関係しています。今の座標系はWGS84[EPSG:4326]という地理座標系です。これを聞いてピンと来なければ一コマめの授業資料やこのサイトをみてみましょう。理解できたら、地理座標系から投影座標系に変換します。
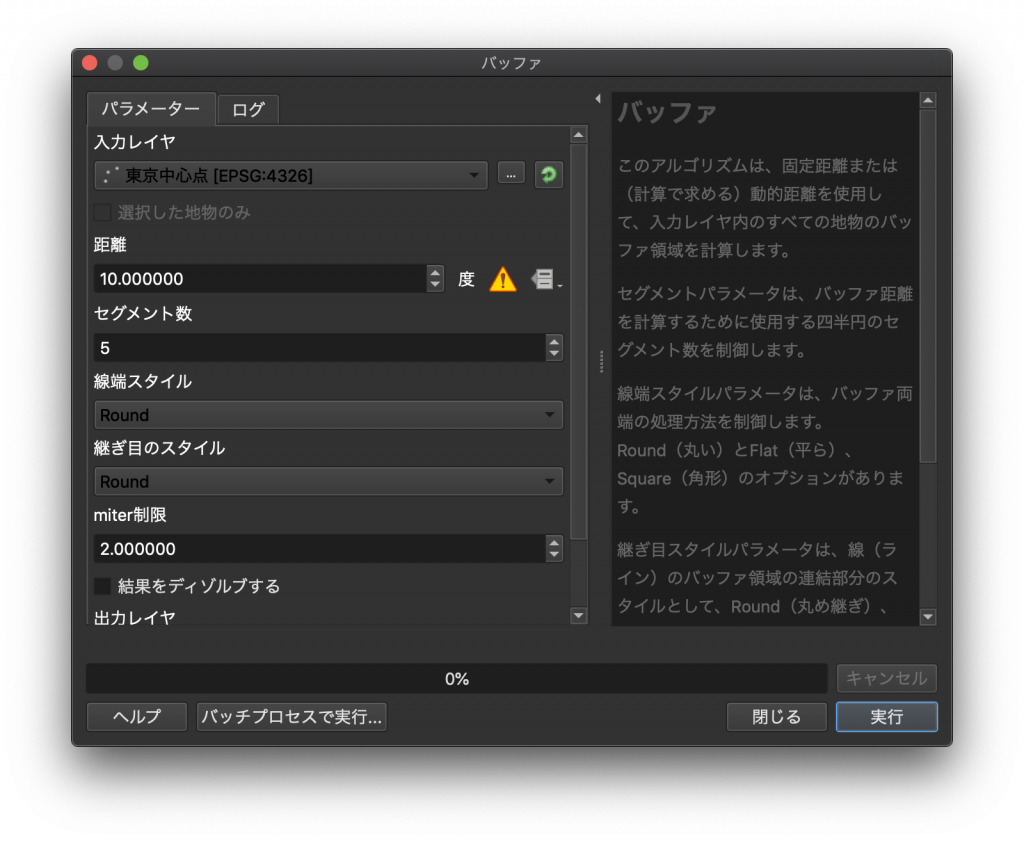
(4) 地理座標系から投影座標系への変換をしましょう。レイヤプロパティから東京中心点を右クリックして、「エクスポート」→「地物の保存」と進みます。まず、ファイルの保存場所(東京中心点.shpと同じ場所)や保存名(このデモでは東京中心点9)を設定します。次にCRS(座標系のこと)を設定します。下図で赤く囲った枠をクリックしてみましょう。
(5) フィルター欄にJGD2000と打ってみましょう。そうすると「あらかじめ定義されたCRS」の「投影された座標系」の下に「JGD2000 / Japan Plane Rectangular CS IX」が出てくるので、これを選択して右下のOKをクリックしましょう。なお右下に地図が出ていますが、「JGD2000 / Japan Plane Rectangular CS IX」の対応するエリアが可視化されたものです。JGD2000の投影座標系には18種類あり、解析の対象とするエリアに合わせて選択しましょう。
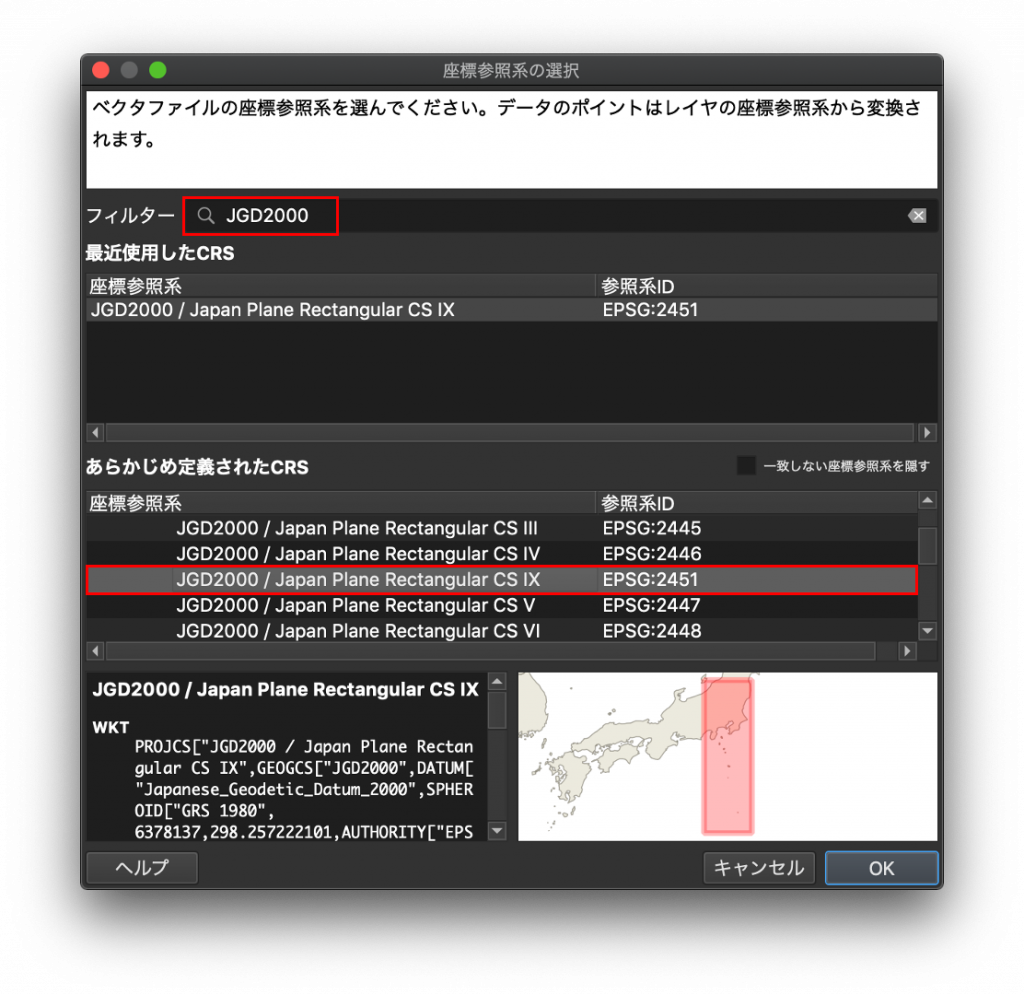
(6) 先ほどのエクスポートの画面に戻ったら、右下のOKをクリックします。
(7) そしてもう一度上のメニューバーから「ベクタ」→「空間演算ツール」→「バッファ」を選択します。

(8) 入力レイヤを「東京中心点9」にすると、距離の単位が選択できるようになります。そこで単位を「キロメートル」に設定します。距離は10のまま実行をクリックしましょう。
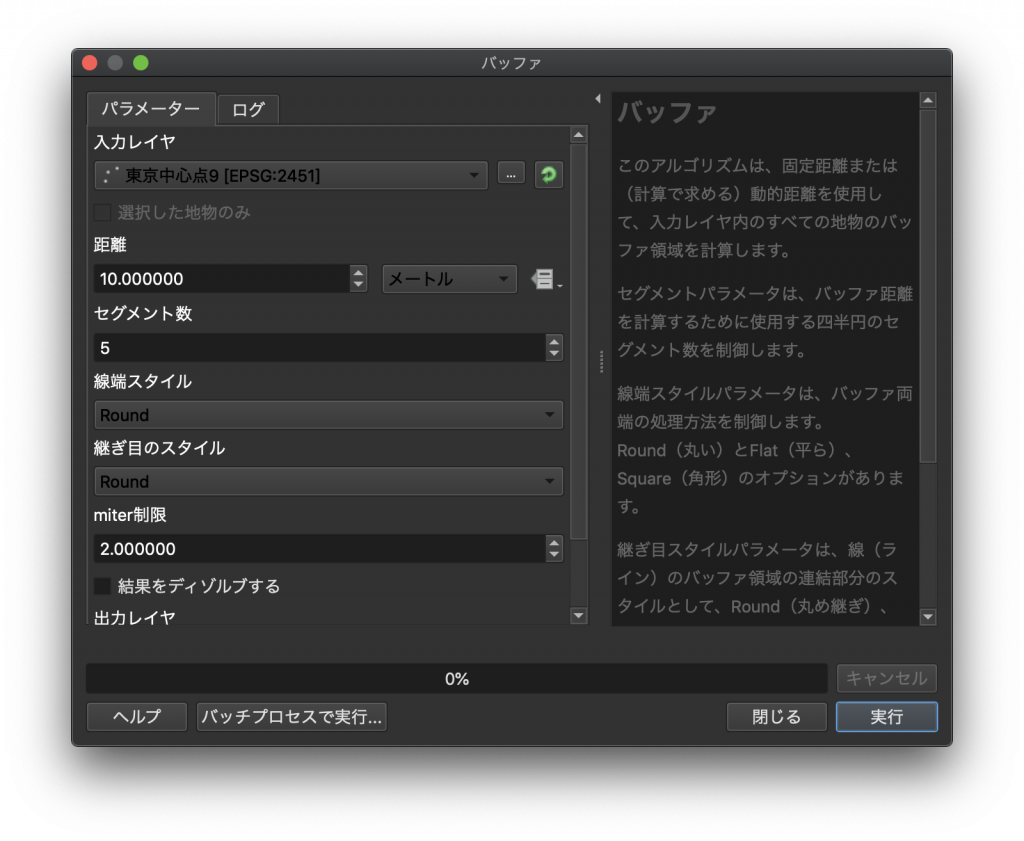
(9) そうすると10km圏にバッファが描かれた地図が出てきます。では、ドーナツ状に10kmごとのバッファを作成したい時どうすればいいでしょうか。10km, 20km, 30km, 40km, 50kmとバッファを作成して、それぞれ内側のバッファを消すという方法もあります。しかし、やや面倒です。
(10) こうした時に使えるのが多重リングバッファというものです。このツールはデフォルトではありません。QGISはデフォルトの機能は必要最低限であり、プラグインを用いて機能を拡張することができます。メニューバーから「プラグイン」→「プラグインの管理とインストール」を選択します。
(11) 検索ウインドウに下図のように「Multi-distance buffer」と入力すると、下のウインドウに「Multi-distance buffer」が出てきます。これを選択し、右下に出てきたインストールボタンをクリックします。インストールが終わったら、右下の閉じるをクリックしましょう。
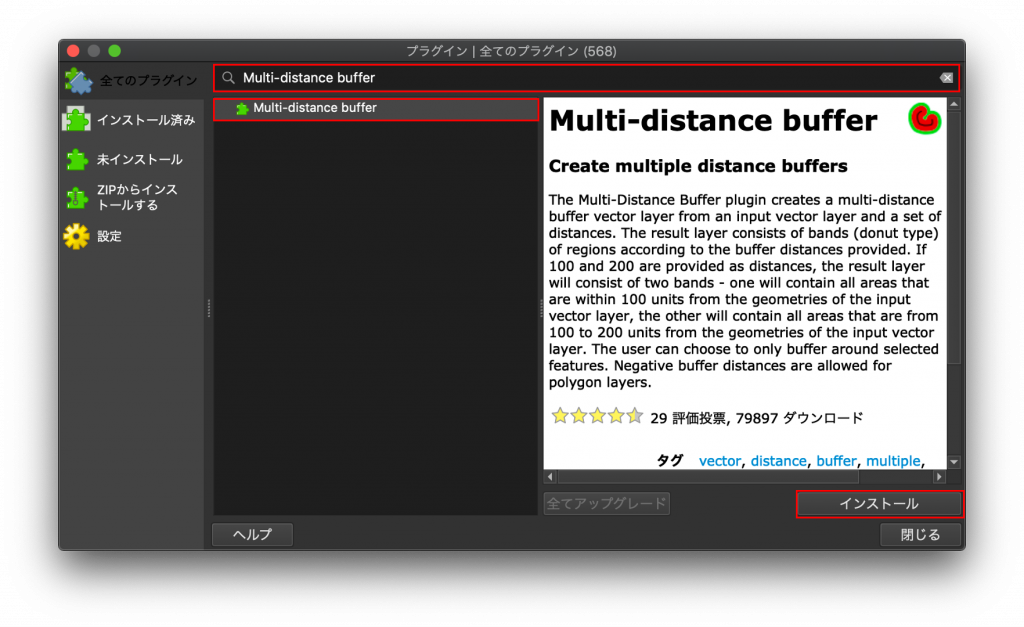
(12) メニューバーから「ベクタ」→「Multiple Distance Buffer」→「MultiDistanceBuffer」を選択します。Input layerを「東京中心点9」に設定し、Buffer distancesからAdd multipleを選択して、下図の通り設定したら「Add」をクリックします。Distancesのウインドウに反映されたことを確認したら、右下のOKをクリックしてCloseをクリックします。これによって10km, 20km, 30km, 40km, 50kmとバッファを作成することができます。
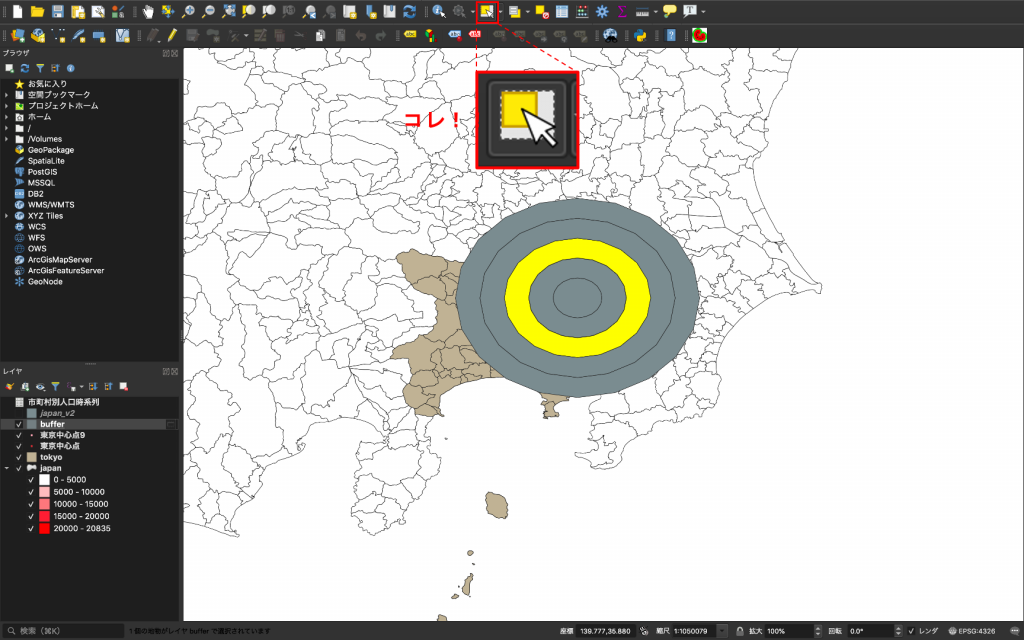
(13) ちゃんとドーナツ状にリングができたか確認してみましょう。下図のように「シングルクリックによる地物選択」をクリックしたら、できたバッファをクリックしてみましょう。下図のようにドーナツ型に表示されれば成功です。
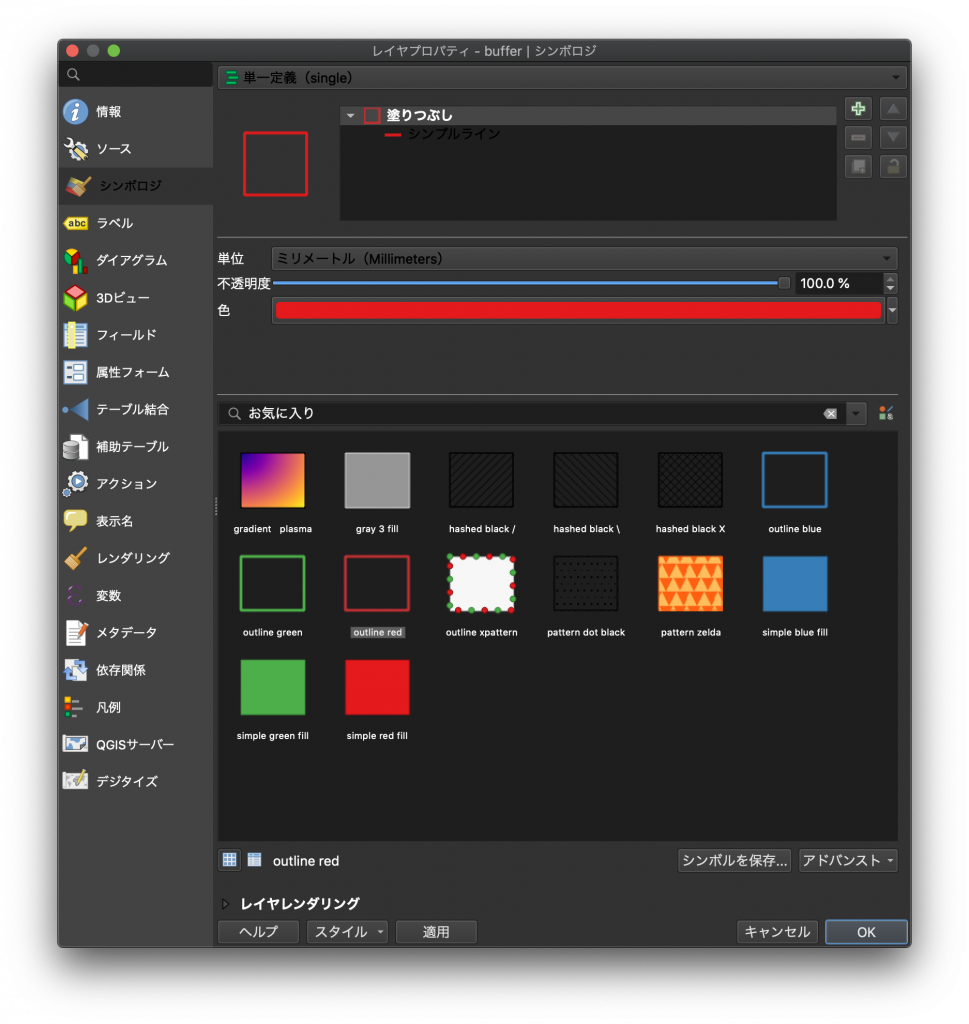
(14) バッファが塗り潰された状態だと見づらいので、色を変えてみましょう。レイヤプロパティの「buffer」を右クリックし、プロパティを開きます。左のメニューからシンポロジを選択し、お気に入りの中から「outline red」を選び、右下のOKをクリックします。
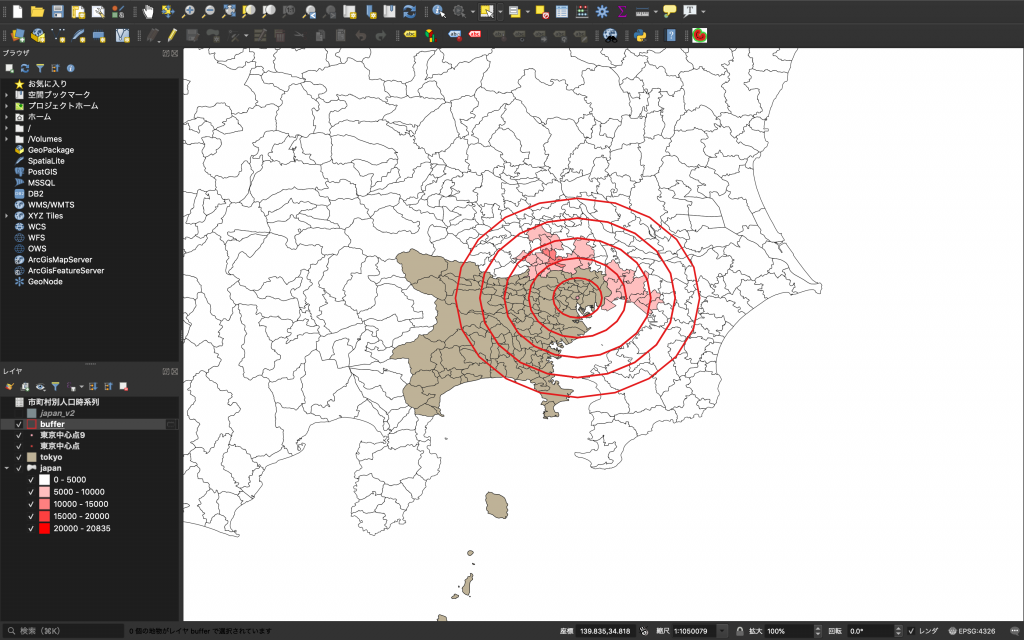
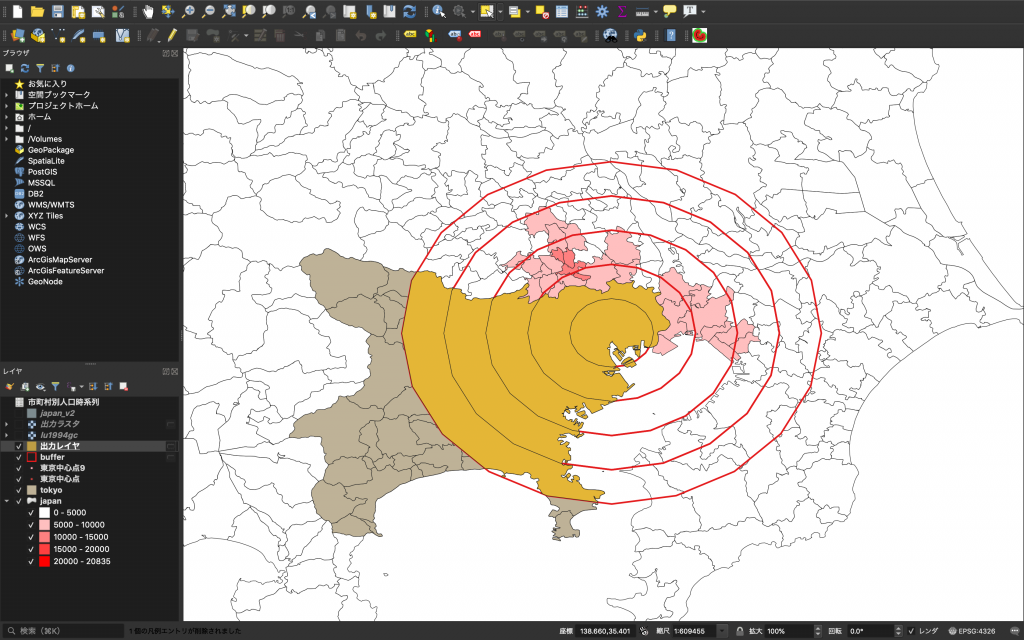
(15) 下図のようになり、下のデータが見えるようになりました。
5. クリップによる対象地域の抽出
バッファポリゴンは範囲が東京都と神奈川県以外に及んでいるため,対象地域のみ抽出します。
(1) メニューバーから「ベクタ」→「空間演算ツール」→「切り抜き(clip)」を選択します。

(2) 入力レイヤに「buffer」、オーバーレイレイヤに「tokyo」を選択し、右下の実行をクリックします。
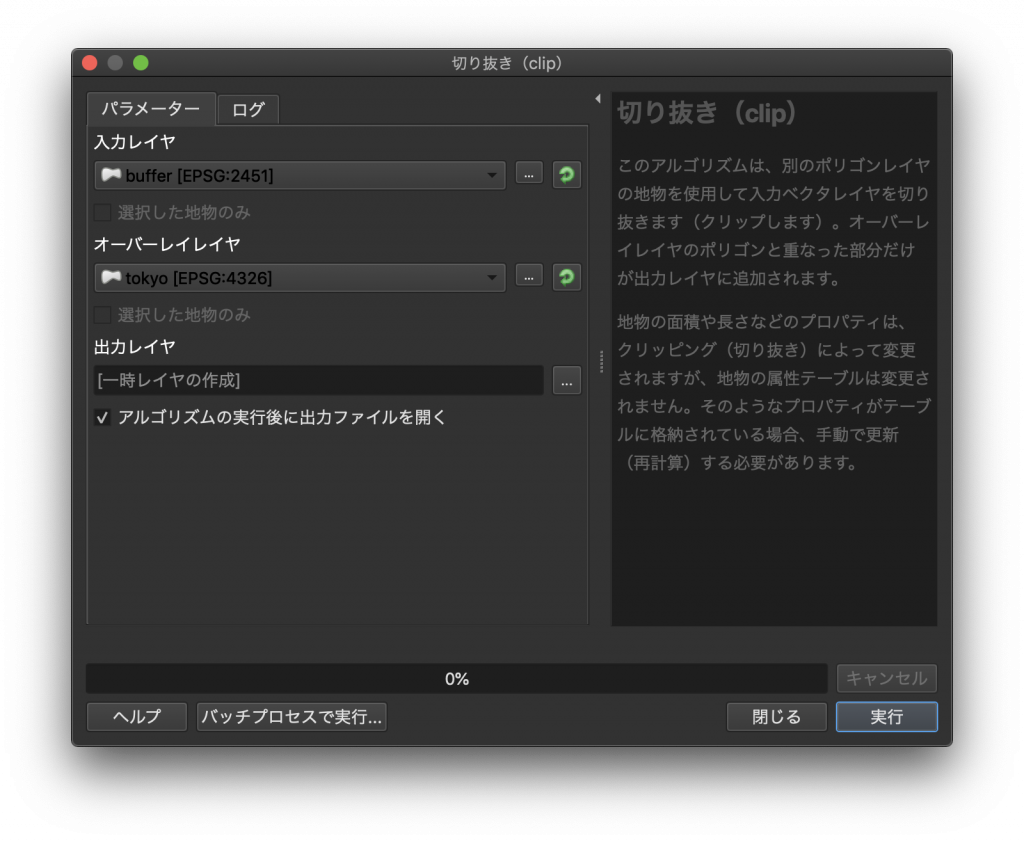
(3) できたデータは一時レイヤとして「ベクタレイヤ」という名前でレイヤウインドウに追加されています。
6. ラスターデータの取り込み
次に、ダウンロードしたもう一つのデータを扱っていきます。このデータは今までのデータ(ベクターデータ)と異なり、ラスターデータです。この違いがわからない場合は、もう一度一コマ目の授業資料を確認してみましょう。
(1)「データソースマネージャを開く」をクリックし、データソースマネージャを開きます。開いたら左側のメニューから「ラスタ」を選択しましょう。そして、ソースの右側にある「…」から「lu1994gc.img」を選択し、右下の「追加」をクリックします。
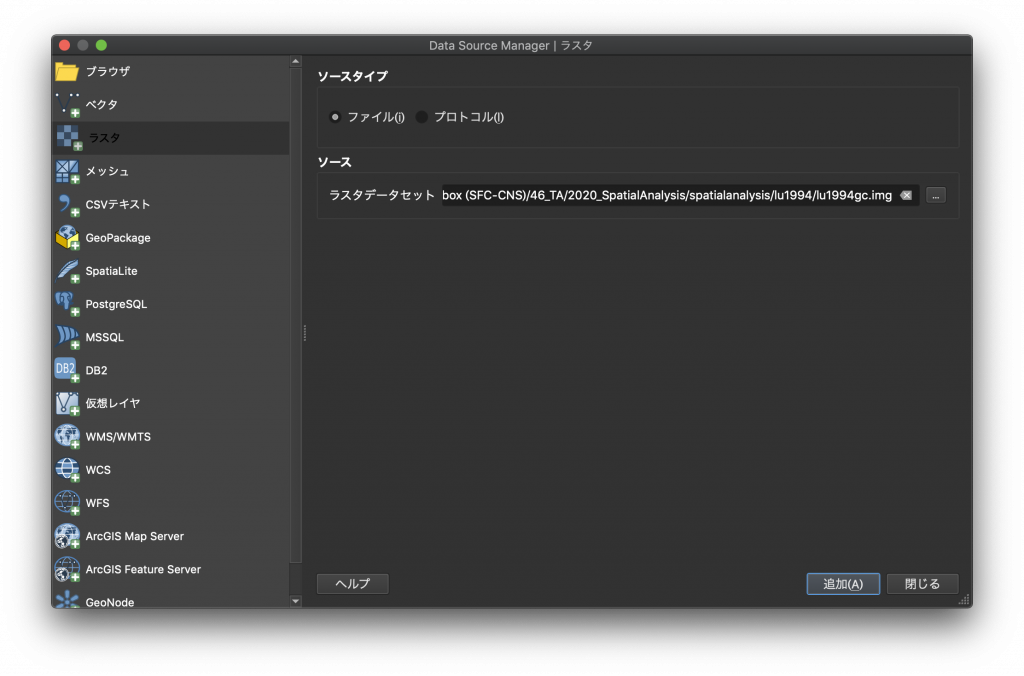
(2) このように表示されたでしょうか。
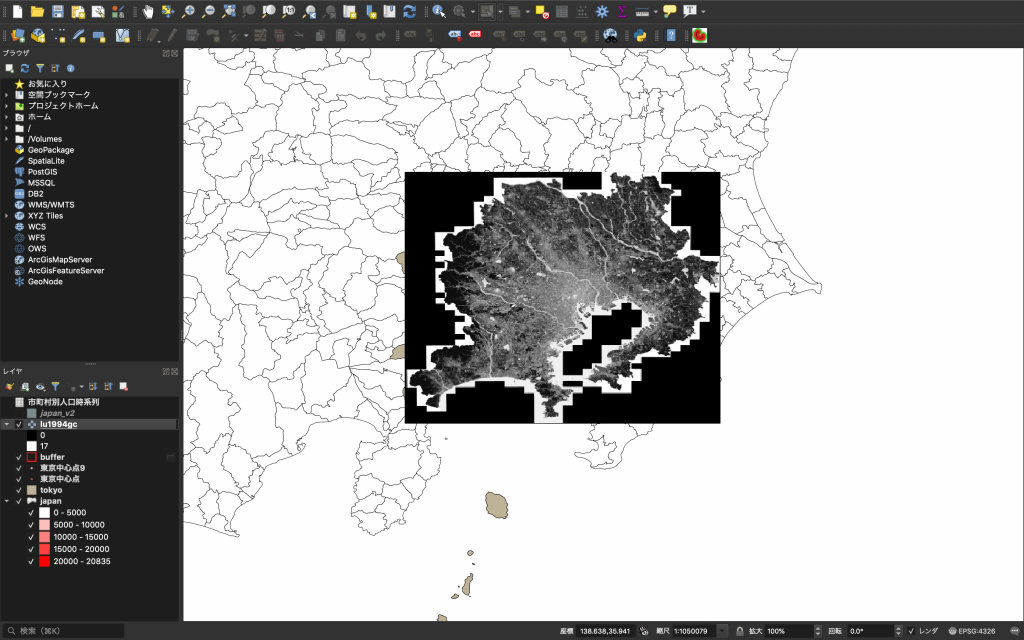
(3) ところで、このデータの名称は「土地利用細分メッシュデータ」といいます。つまり、どの土地利用(例えば、田、工業用地など)か判別されたデータです。この分類は下の表に示す通りですが、今回の分析に用いるには詳しすぎるので、もう少しざっくりしたデータに変えたいと思います。この作業を「再分類」と言います。
| 初期値(土地利用小分類) | 意味(土地利用小分類) | 新規値(土地利用大分類) | 意味(土地利用大分類) |
|---|---|---|---|
| 0 | 対象地域外(沖合、首都圏外) | 7 | 対象地域外 |
| 1 | 山林・荒地等 | 1 | 山林・農地等 |
| 2 | 田 | 1 | 山林・農地等 |
| 3 | 畑・その他農地 | 1 | 山林・農地等 |
| 4 | 造成中地 | 2 | 造成地 |
| 5 | 空地 | 2 | 造成地 |
| 6 | 工業用地 | 3 | 宅地 |
| 7 | 一般低層住宅地 | 3 | 宅地 |
| 8 | 密集低層住宅地 | 3 | 宅地 |
| 9 | 中高層住宅地 | 3 | 宅地 |
| 10 | 商業・業務用地 | 3 | 宅地 |
| 11 | 道路用地 | 4 | 公共公益施設用地 |
| 12 | 公園・緑地等 | 4 | 公共公益施設用地 |
| 13 | その他の公共公益施設用地 | 4 | 公共公益施設用地 |
| 14 | 河川・湖沼等 | 5 | 河川・湖沼等 |
| 15 | その他(防衛施設・皇居等) | 6 | その他 |
| 16 | 海(海岸線付近) | 7 | 対象地域外 |
| 17 | 対象地域外(対象地域 境界付近) | 7 | 対象地域外 |
| 255 | 対象地域外 | 7 | 対象地域外 |
(4) メニューバーから「プロセシング」→「ツールボックス」を選択すると画面右に「プロセシングツールボックス」が開きます。
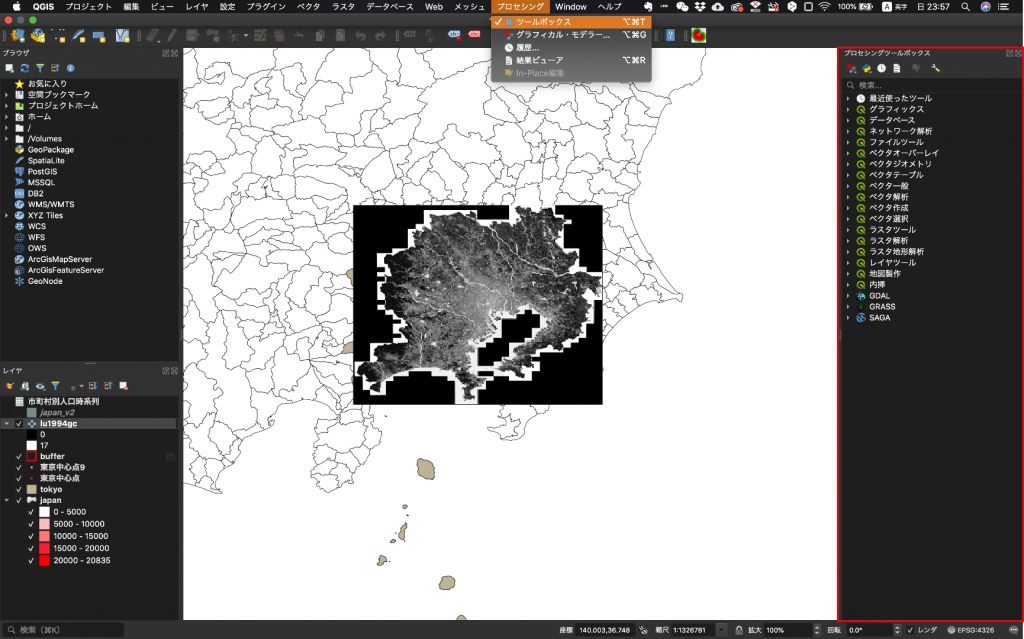
(5) そして検索ウインドウに再分類を意味する「reclass」と入力してみましょう。そうすると、下に出てきた「ラスタ解析」→「テーブルによる再分類」(現在は「区分表で再分類」に名前が変わっています)をクリックします。
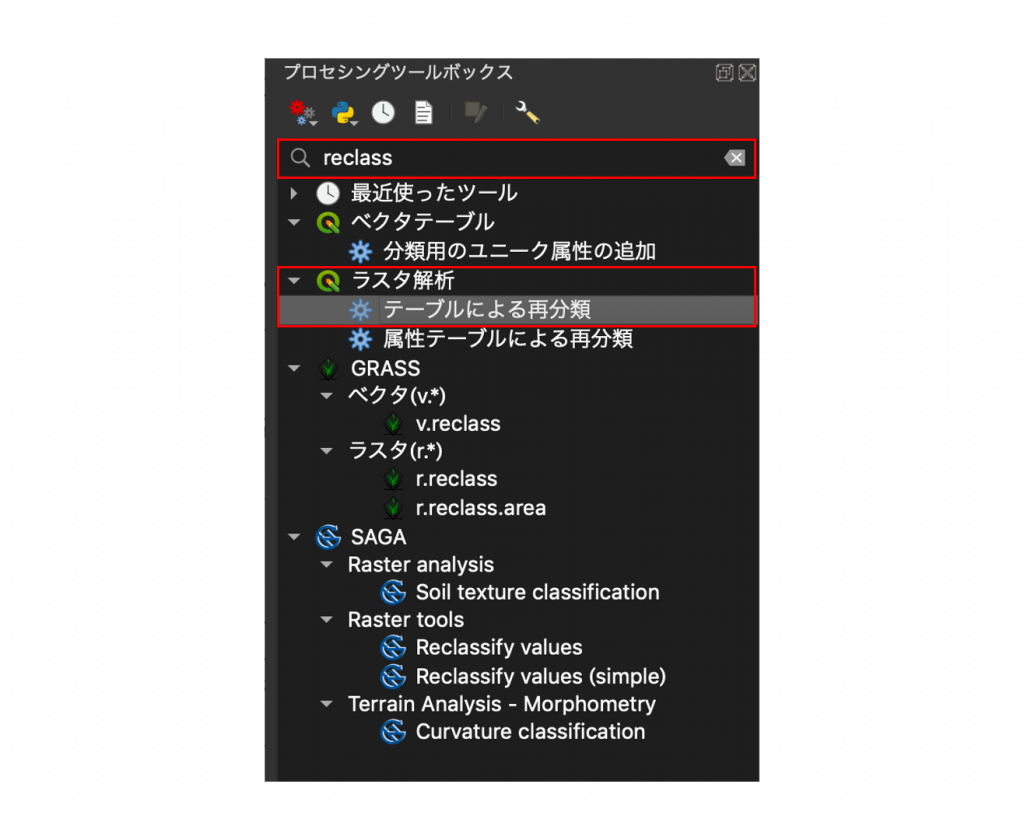
(6) テーブルによる再分類が開いたら、下図の赤枠で囲ったボタン「…」をクリックします。
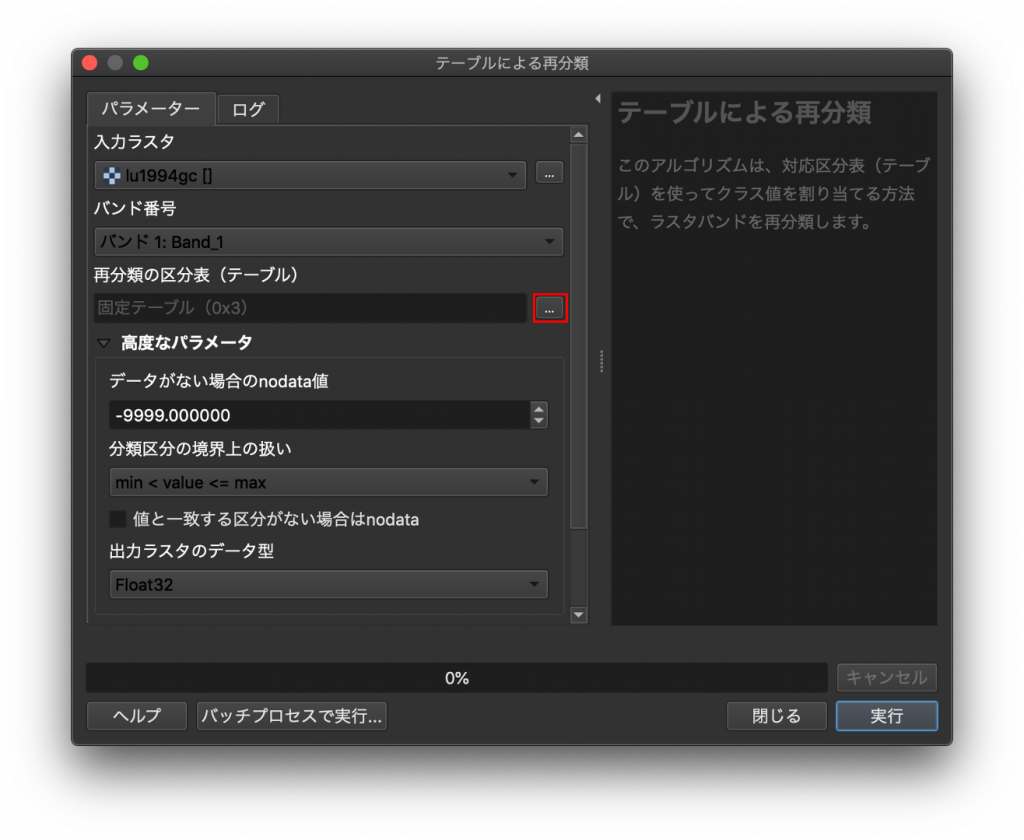
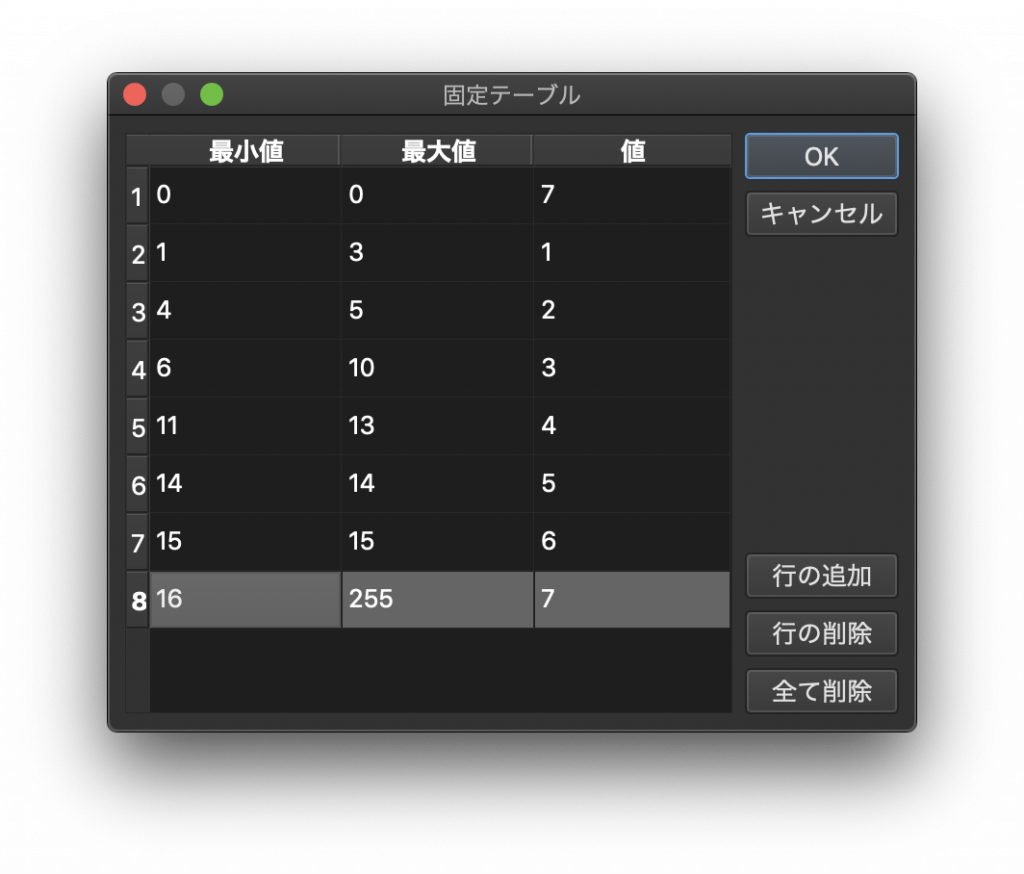
(7) 右下の「行の追加」ボタンをクリックして8行分追加したら、下図のように表を埋めます。この値は先ほどの土地利用細分表に対応しています。
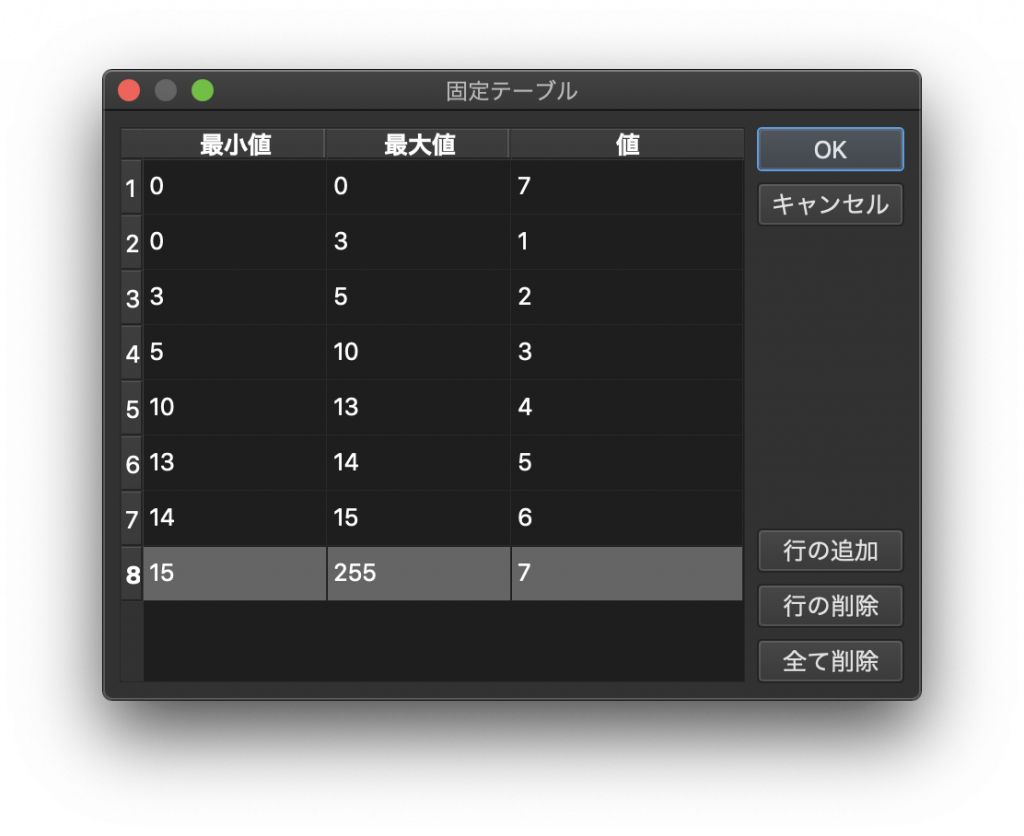
(7)’ しかし、なぜ下図のように記載しないのでしょうか。その理由は(9)でご説明することにしましょう。とにかくOKをクリックして画面を閉じます。
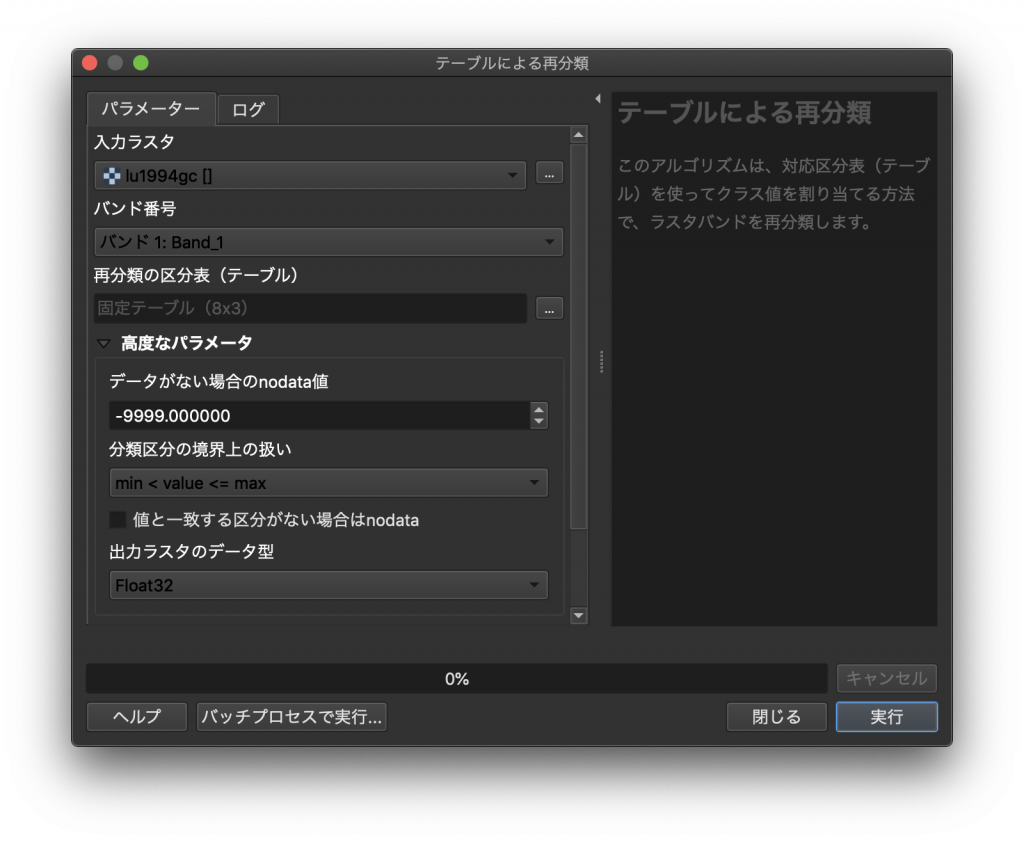
(8) この画面に戻ったら、右下の実行をクリックします。
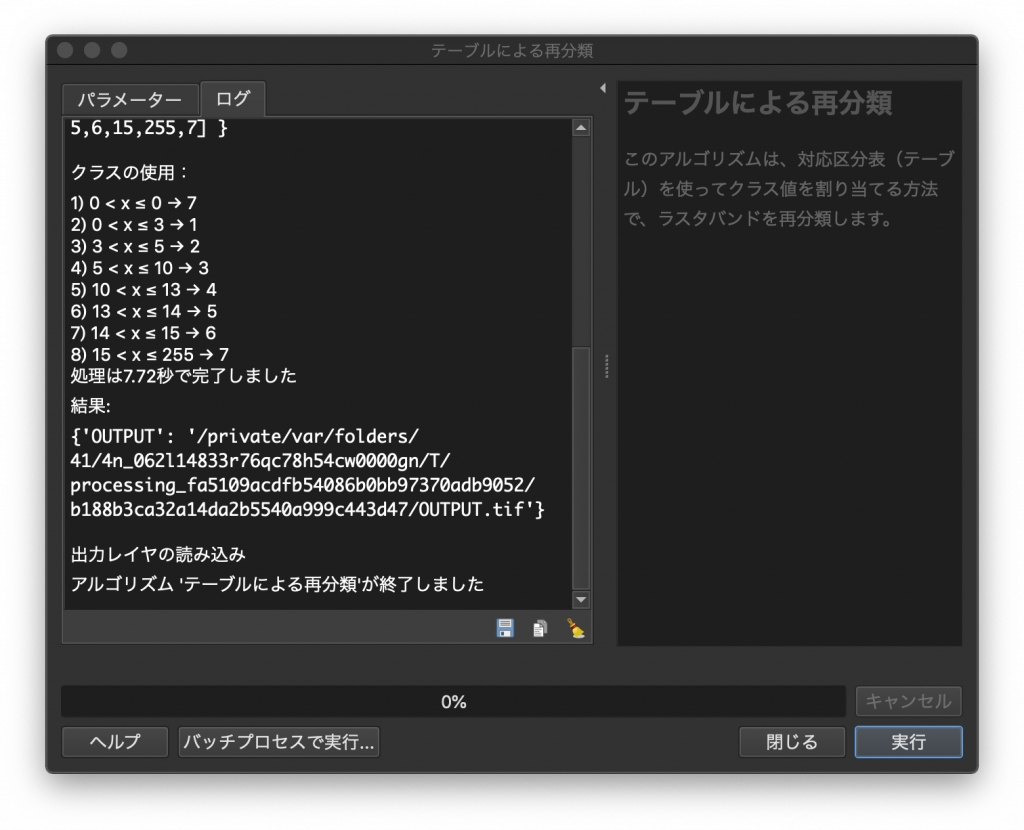
(9) 下図のような画面に遷移します。ここで左のウインドウを見てみましょう。最小値のほうは「<」が使われており、最大値の方は「≦」が使われています。つまり最小値に入力した値そのものは再分類に使われていないのです。これで(7)と(7)’での疑問が解決したのではないでしょうか。
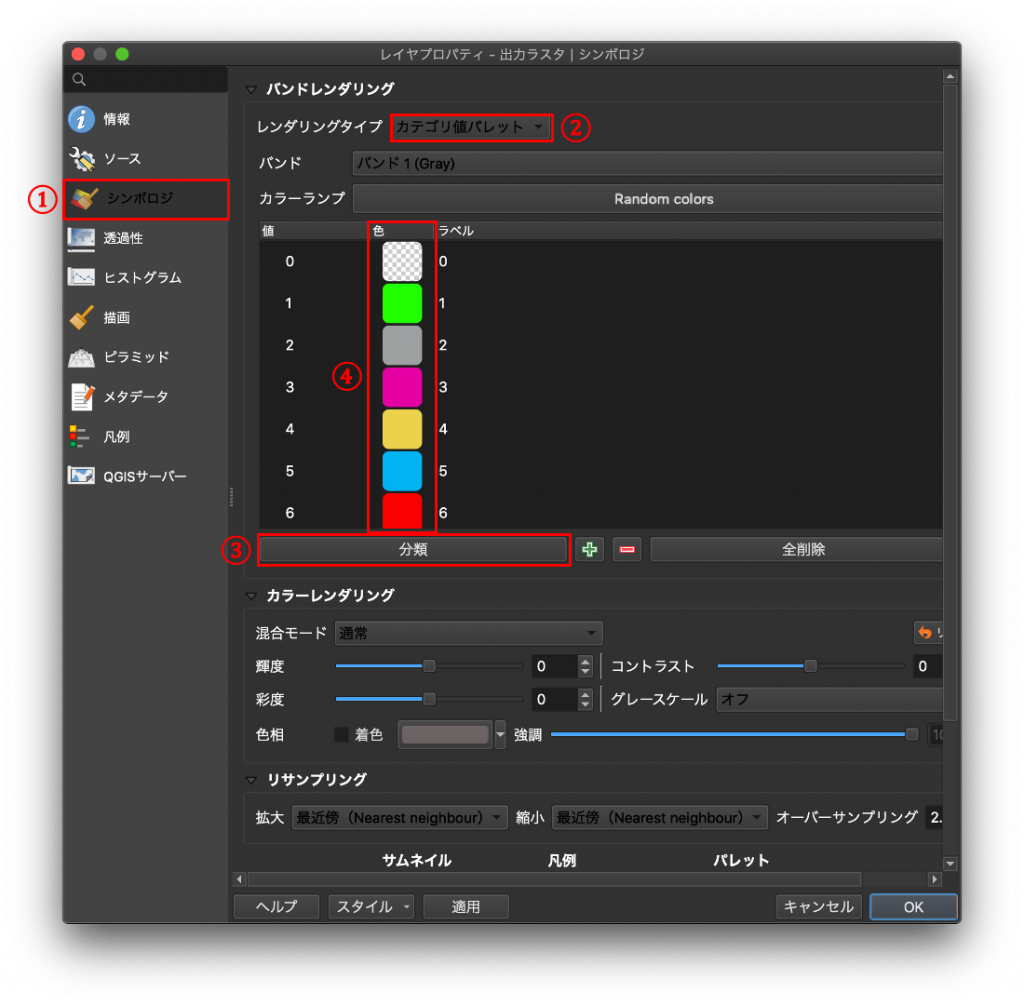
(10) 再分類した結果は「レイヤプロパティ」に「出力ラスタ」という名前で追加されています。コレを右クリックし、プロパティを開きます。プロパティを開いたら左のメニューで「シンポロジ」を選択し、レンダリングタイプを「カテゴリ値パレット」を選びましょう。次いで分類をクリックすると値に応じて色が振り分けられます。ここで設定された色は適当なので、先ほどの土地利用細分表を見て色を設定してみましょう。終わったら右下の「OK」をクリックします。
(11) 下図のように表示されていればOKです。
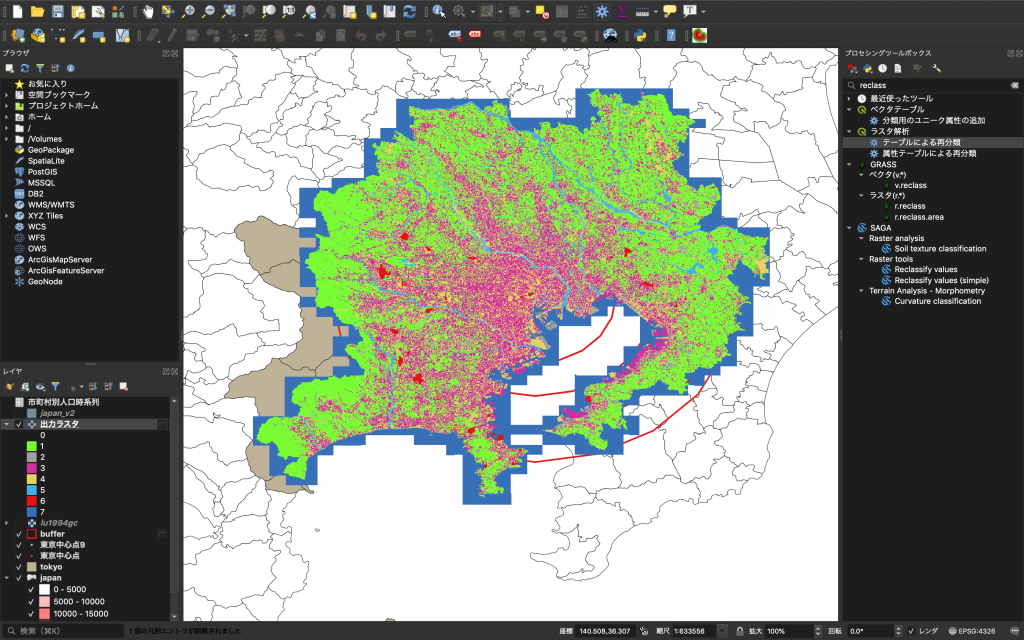
7. バッファによる距離帯別集計
10km毎の圏域について,土地利用別の面積を集計します。
(1) メニューバーから「プロセシング」→「ツールボックス」を選びます。
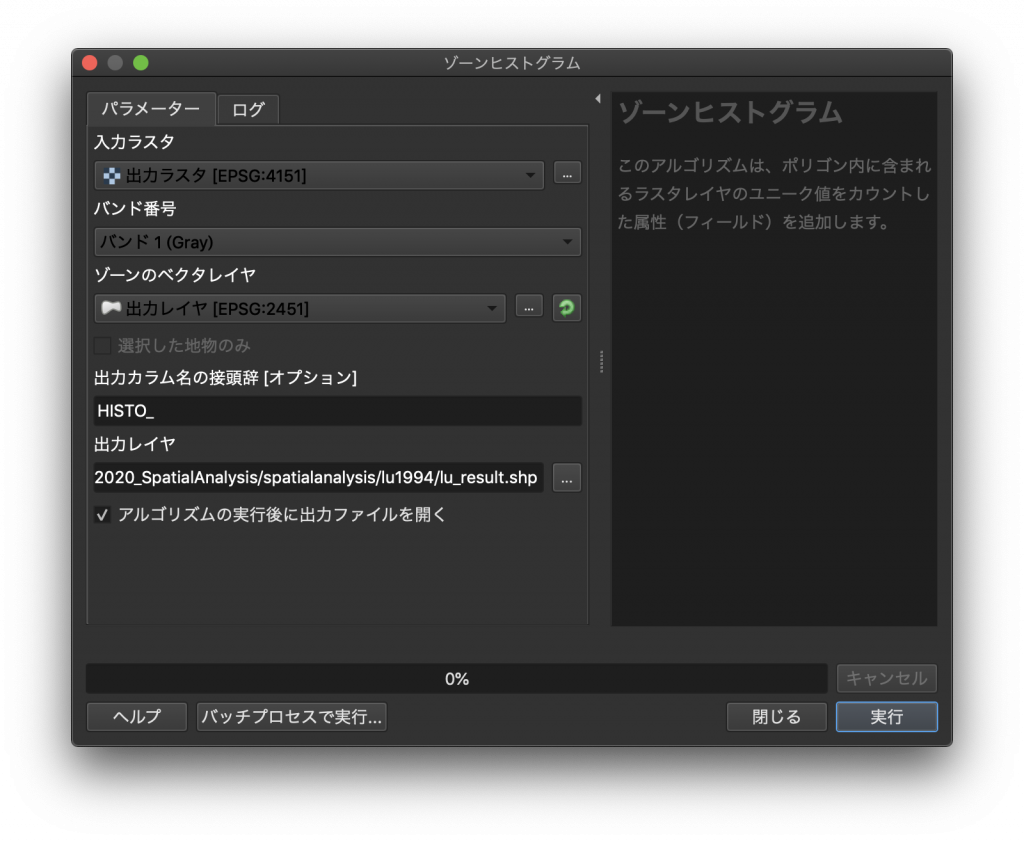
(2) 画面右に出てきた「プロセシングツールボックス」から「ラスタ解析」→「ゾーンヒストグラム」を開きます。
(3) 入力ラスタで「出力ラスタ」、ゾーンのベクタレイヤで「出力レイヤ」をそれぞれ選びます。次に、出力レイヤの欄でファイルの保存場所と保存名を選びましょう。このデモでは、「spatialanalysis」→「lu1994」のフォルダの下に「lu_result.shp」という名前で保存しています。全て設定し終えたら、右下の実行ボタンをクリックしましょう。そして実行が終わったら、「閉じる」をクリックします。
(4) レイヤプロパティの中の「lu_result」を右クリックし、属性テーブルを開きます。そうすると距離がdistance列に確認でき、再分類した7までの結果が「HISTO_?」という形で列名になっていることがわかります。

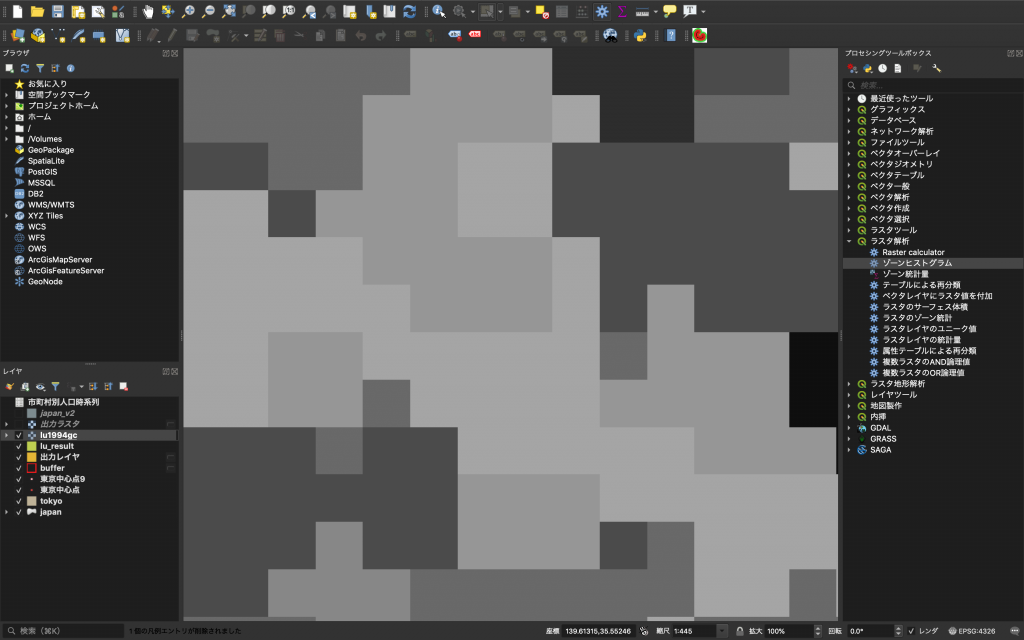
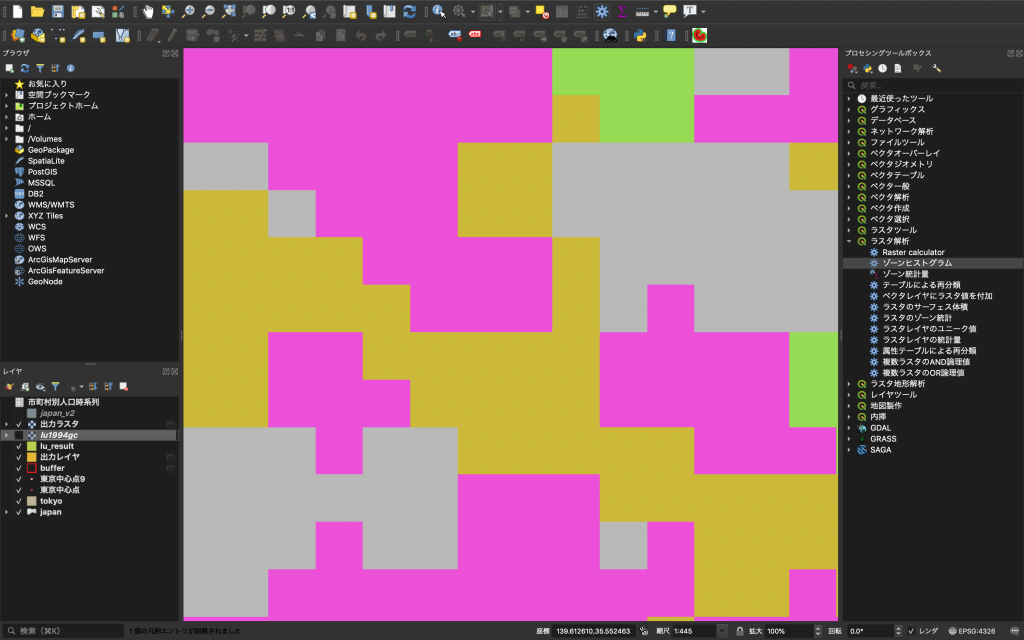
(5) ところで、この「HISTO_?」の下にある数字はなんでしょうか。「lu1994_gc」か「出力ラスタ」を表示した上で地図を拡大してみてください。そうすると下図のように見えることでしょう。このようにラスタデータは「セル」というものの集合でできています。この「セル」がいくつかるかというデータが「HISTO_?」の各欄に記載されています。
(6) 今回のデータは、10mメッシュと呼ばれるものです。つまり一つのセルは100m2です。ここから面積を割り出すこともできます。
(7) ではこの属性データを書き出してみましょう。レイヤプロパティからlu_resultを右クリックし、「エクスポート」→「地物の保存」と進みます。「ベクタレイヤを名前をつけて保存」ウインドウが開いたら形式を「カンマで区切られた値[CSV]」を選択し、ファイル名でlu_result.shpと同じ場所にlu_result.csvとして保存します。また、このデータはQGISで必要ないので、一番下の「保存されたファイルを地図に追加する」というチェックボックスは外して構いません。以上完了したら、右下の「OK」をクリックします。
(8) 保存したフォルダからlu_result.csvを開きます。「distance」列と「HISTO_1」から「HISTO_4」までの列以外は削除します。そして「distance」の文字は削除し、値をそれぞれ「10km」「20km」「30km」「40km」「50km」としましょう。また「HISTO_?」の列の名前はそれぞれ、「山林・農地等」「造成地」「宅地」「公共施設用地」に変えてみましょう。
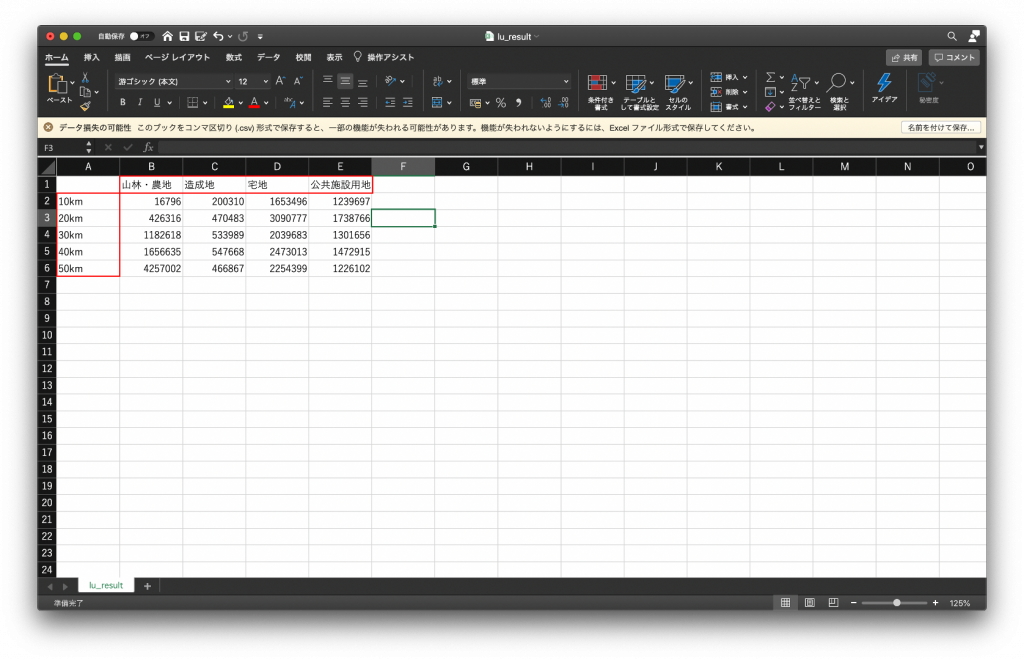
(9) 「挿入」タブをクリックし、データを選択します。そして棒グラフの中から積み上げ棒グラフを選択します。
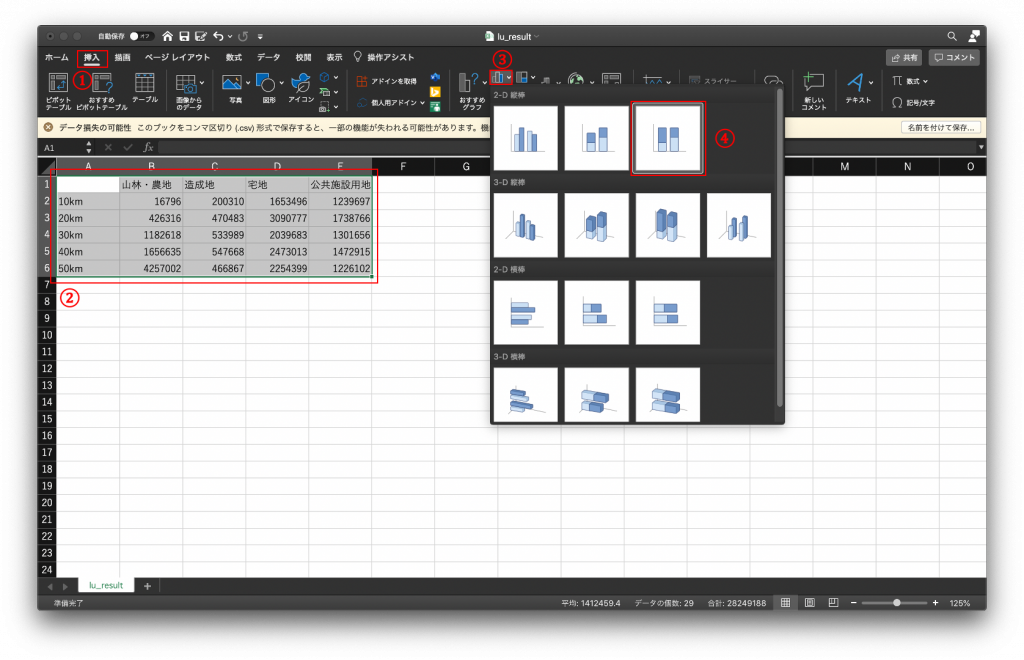
(10) 出てきたグラフの横軸が距離になっていれば成功です。もし横軸が土地利用になっていれば、「グラフのデザイン」タブから行/列の切り替えを行います。
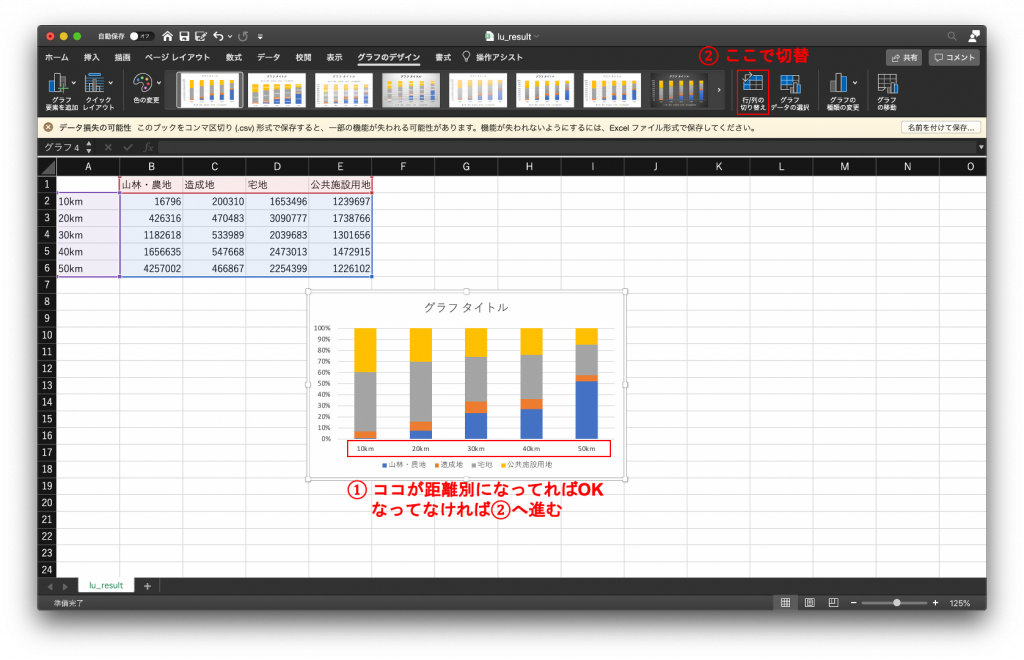
生成されたグラフを見ると、都市部から離れるに従って、山林・農地等の割合が大きくなるという典型的な地域構造が読み取られます。この分析結果のみではこれ以上に何かを読み取ることは難しいですが、他の統計データとの関連性を見てみたり、駅や線路のバッファを生成してみたりすることで、興味深い考察を得られることでしょう。さらに他のGISデータを導入することで、解析手順は多岐に渡り、分析や考察も多面的に得られると思います。今回の分析手順を参考として、各自興味のある分野について、様々な分析を試みてみてください。
2020.9.25 QGIS版 初版(政策・メディア研究科 博士課程 1年 中山俊)
2024.10.22 第二版 (政策・メディア研究科 特任助教 中山俊)